In this discussion, I will share about the modern data pipeline tech stack, based on my experience as a data engineer and current technology trends.
I will explain why I chose the data tech stack, Here’s the data architecture design:
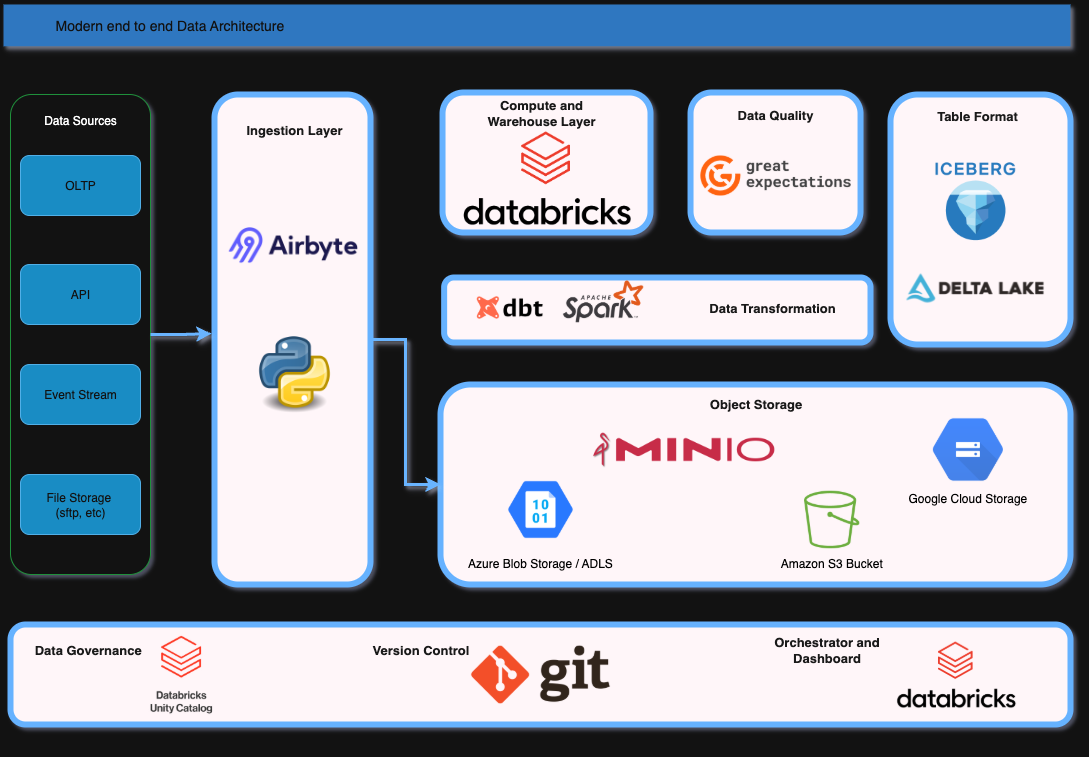
A. Ingestion
I would choose Airbyte to extract data and load it into object storage. Airbyte supports extracting from APIs, OLTP databases, and file storage.
However, depending on the use case, I often prefer writing custom Python scripts to pull data directly from the source system and load it into the raw bucket.
B. Storage
For storage, I’m flexible: S3, Azure Blob Storage, Google Cloud Storage, or MinIO for on premise.
It depends on the company’s existing architecture and infrastructure strategy.
C. Compute & Transformation
I would choose Databricks because it’s a modern data platform. It allows us to build Spark jobs or dbt jobs for transformations, and provides a collaborative workspace for both data engineers and analysts. It natively supports Spark, notebooks, and workflows.
Spark: Ideal for handling large scale or streaming data.
dbt: Great for moving data from staging to silver and silver to gold layers using SQL. It helps define business logic in a query-based approach.
D. Data Quality
For data quality, I would use Great Expectations (GX). It provides expectation suites where we can define validations in JSON files.
We can also create custom expectations for Pandas, Spark, or dbt. GX returns rows that fail validation, making it easy to track and debug issues.
E. Orchestration
If we stay within Databricks, we can use its Jobs & Pipelines feature to manage pipelines.
However, my personal recommendation is Apache Airflow. Airflow is still the best option for me if you want orchestrate your job without using databricks, offering scheduling, retries, backfills, and sensors for waiting on data.
F. Table Format
I would choose either Apache Iceberg or Delta Lake, depending on ecosystem and integration needs.
Delta Lake: Best with Databricks since it’s natively supported and provides versioning, schema enforcement, and ACID transactions. Delta lake it's a default storage format in databricks.
Apache Iceberg: A great alternative with similar features (versioning, schema evolution) but supports multiple engines like Trino, Flink, and Spark. Databricks also supports creating and working with Iceberg tables.
G. Data Governance
With Databricks, we can implement governance using Unity Catalog. It allows fine grained access control for tables and columns, including sensitive data, using attribute-based access control and row/column level security.
For open source alternatives, DataHub is a good option. It provides features like data ownership, lineage, and user access management with roles and policies.